
Machine Learning for Stock Trading, Part 1: Data Acquisition
A framework for acquiring financial time series data
Introduction
In this series, I will break down complex Machine Learning (ML) and artificial intelligence (AI) topics in a way that anyone can understand. If you are either 1) interested in applying machine learning techniques to stock trading, or 2) considering investing in a quantitative fund/strategy/manager and want to learn more about machine learning , then this series is a great starting point. This series will be based on Python since I use it for all my machine learning code. Note that this series is meant to be used as a framework/checklist for your machine learning project, and I will not be doing a deep dive on technical concepts and skills. I encourage you to perform additional research as you encounter subjects where you need a deeper understanding.
In this piece, I will lay out a high-level framework for acquiring financial time series data. Data is the most important aspect of any machine learning project. There is a common saying in machine learning: “Garbage in, garbage out.” In other words, it doesn’t matter how good a model is, its results will only be as good as the underlying data. That’s why it’s extremely important to spend extra time in the beginning to get the data right.
1. Data Sources
There are many sources from which you can obtain financial data. Some are easier to use than others. Here are some common sources:
Kaggle: Kaggle offers many free datasets that can be used for stock trading.
Nasdaq Data Link: Formerly called Quandl, this site offers many free and paid datasets that can be accessed through bulk CSV download and their API.
Polygon: Acquire free and paid financial market data through their API.
Other common sources include S&P Capital IQ, Factset, and Bloomberg; however, these options are very expensive and typically only used by financial professionals.
2. Types of Financial Data
There are five common types of financial data: price, fundamental, estimates, macroeconomic, and alternative.
2.1 Price Data
Price data primarily includes price and volume data for stocks, options, and other assets. It will typically have a daily frequency, although will sometimes also be available at intraday intervals. For example, daily datasets often include the open, high, low, and close prices for stocks as well as the daily volume. Intraday datasets might include hourly or even minute-by-minute data. Choose the frequency of data that best fits your target variable. If you are generating signals days or weeks into the future (usually for longer-term trading), then daily data will suffice. If you are generating intraday signals for day trading or high-frequency trading, then you must use intraday data. Price data is typically used to generate price/volume related features and/or technical indicators, such as moving averages and momentum indicators.
2.2 Fundamental Data
Fundamental data includes all company-specific financial data. Fundamental data is typically released by public companies on a quarterly basis through financial statements filed with the SEC. The three main financial statements are the income statement, balance sheet, and cash flow statement. Fundamental data includes line items such as revenue, gross margin, EBITDA, net income, EPS, assets, liabilities, and retained earnings, among many others. These items allow investors to assess the financial strength of companies. Fundamental data is typically used to calculate growth, margins, and multiples, all of which can be used as inputs in machine learning models.
2.3 Estimate Data
Estimate data includes all data that forecast a company’s future financials. This data can come from primary or secondary sources. A primary source would include a company providing guidance about its future earnings. This is often done every quarter on earnings calls and in 8-K filings. Secondary sources include equity research. Equity research shops, such as Morgan Stanley and Goldman Sachs, employ a team of analysts that create financial models for the companies that they cover. These models include forecasts of key fundamental line items that can be used as inputs to machine learning models.
2.4 Macroeconomic Data
Macroeconomic data is self-explanatory. It includes all data related to the economy as a whole, whether regionally (e.g. USA) or globally. Common macro data includes GDP, inflation, and Treasury yields. This data is useful if you are trying to predict large trends in addition to company-specific ones.
2.5 Alternative Data
Alternative data is a newer type of data and encompasses all non-traditional data that may or may not be correlated with the performance of a company. Some examples include social media sentiment, satellite imagery, credit card transaction data, app usage data, among others. Prior to COVID, some hedge funds famously used a combination of credit card transaction data and satellite imagery of mall parking lots in order to accurately predict earnings outcomes of many retail companies. You can get really creative in sourcing and using alternative data.
3. Shape of Data
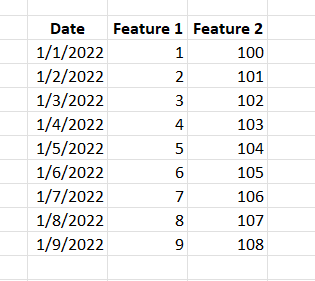
What shape (i.e. format) of data is best? For financial time series data, it will generally be two-dimensional with the date on the y-axis and features on the x-axis.
Pandas is an amazing library for all things data related and is the industry-standard for what machine learning researchers use to process data. It is essentially like Excel on steroids built especially for Python.
4. Properly Identifying Stocks
Properly identifying stocks is something that is often overlooked by machine learning researchers. You may be thinking that identifying a stock is as easy as using its ticker, however, you’d be mistaken.
4.1 Ticker Sharing
The first problem is that multiple companies can share the same ticker. This can happen when a company stops trading, then a different company takes on the same ticker at a future point in time. This can also happen if two different companies are trading with the same ticker, but on different exchanges (e.g. NYSE vs international).
4.2 Ticker Changes
The second problem is that a company may change its ticker. This can happen if a company changes its name or rebrands.
4.3 Multiple Share Classes
The third problem is that a company may have multiple classes of shares trading, e.g. Google trades under tickers GOOGL and GOOG. How would you handle the difference between price and fundamental data in these instances?
I recommend generating unique identifiers for each entity that is separate from its ticker. This way, potential mix-ups are avoided.
5. Aligning Dates and Times
If you are combining multiple datasets, it’s important to make sure that the dates and times line up properly.
5.1 Aligning Different Temporal Frequencies
For example, say you are merging two datasets. Dataset 1 includes intraday data released multiple times a day, and dataset 2 includes daily data that is released once a day at market close. You want to align the data such that the last daily capture of dataset 1 is aligned with dataset 2. I recommend using pandas timestamps to ensure proper temporal alignment.
5.2 Aligning Time Zones
Another example would be working with data from different time zones. I recommend standardizing all timestamps on the GMT time zone in this case.
6. Aligning Stock Prices
6.1 Stock Splits and Reverse Stock Splits
Just like dates and times must be aligned, so must stock prices. Companies will sometimes perform stock splits or reverse stock splits. Stock splits reduce a company’s stock price by increasing the number of outstanding shares. For example, a 2-for-1 stock split would cut a company’s stock price in half. A reverse stock split increases a company’s stock price by doing the opposite. In either case, you must be careful to normalize such companies’ stock prices in order to avoid potential issues in your machine learning model. I recommend picking one price scale and sticking to it. For example, if a company did a 2-for-1 stock split, you would multiply all share price data points post-split by 2 and divide the number of shares by 2.
7. Avoiding Look-Ahead Bias
7.1 What is Look-Ahead Bias?
Look-ahead bias is a serious problem that must be addressed early in the research process. If not, it could lead to catastrophic losses in real trading. Look-ahead bias occurs when data contains forward-looking information. This causes models to perform much worse in real trading than otherwise indicated in backtests. I will give three common examples.
7.2 Look-Ahead Bias in Price Data
The first example encompasses price data. Let’s say you are using daily OHLCV (open, high, low, close, volume) data to create a model that will trade on a daily basis. The problem here is that OHLCV is not fully known until after the trading day closes. By training your model on this data, you are inadvertently giving it access to forward-looking information. Therefore, your model will not perform well in real trading because OHLCV data will not be available on a real-time basis during the trading day. This issue is unfortunately very widespread in the machine learning financial community.
7.3 Look-Ahead Bias in Fundamental Data
The second example relates to fundamental data. Let’s say you are using fundamental data to create a trading model for Company A, and that Company A releases financials on a quarterly basis. Let’s assume we are analyzing data for the quarter ended March 31st. What happens in reality is that Company A will release preliminary, not finalized, numbers every quarter. So on April 15th (there is usually a two week delay to process data), assume that Company A releases data showing its revenue was $100m. What ends up happening is that in the weeks and months to follow, Company A will release subsequent revisions to the preliminary data. So let’s assume that on May 1st, the company releases an amended revenue number of $95m — this is a significant difference that will affect the company’s stock price.
The problem is that many fundamental datasets only include the revised numbers and not the preliminary ones. So in our example, a typical dataset might show $95m of revenue released on April 15th. This is a huge problem because any model trained with this data would be exposed to forward-looking information. For this reason, I recommend only using fundamental datasets that contain point-in-time series. This type of point-in-time data is often more expensive but is worth it to avoid potential catastrophic losses.
7.4 Look-Ahead Bias in Macroeconomic Data
The last example covers macroeconomic data. Just like fundamental data, macro data is released on preliminary and revised bases. For the same reasons stated above, it’s important to ensure any macro data used is point-in-time.
These are just some common examples of look-ahead bias, but the potential for this issue exists in any and all types of time series data. If you are interested in machine learning time series research, you must be vigilant to prevent it.
Conclusion
Once you have acquired your data and transformed it into a usable format, it’s time to further process the data in order to ensure your machine learning models will have the best chance of success. In the next piece, I will cover exploratory data analysis, data cleaning, and feature engineering.
What about alphaAI?
In any investment endeavor, the key to success lies in making informed decisions. Whether you're building a recession-resistant portfolio, diversifying your assets, or simply exploring new opportunities, your journey should be guided by knowledge and insight. At alphaAI, we are dedicated to helping you invest intelligently with AI-powered strategies. Our roboadvisor adapts to market shifts, offering dynamic wealth management tailored to your risk level and portfolio preferences. We're your trusted partner in the complex world of finance, working with you to make smarter investments and pursue your financial goals with confidence. Your journey to financial success begins here, with alphaAI by your side.
Supercharge your trading strategy with alphaAI.
Discover the power of AI-driven trading algorithms and take your investments to the next level.

Continue Learning
Dive deeper into the world of investing and artificial intelligence to unlock new opportunities and enhance your financial acumen.

Paul Merriman’s Ultimate Buy & Hold Portfolio: Historical Review and Modern Risk Considerations

.jpg)
How AI Safely Manages Leveraged ETFs for Long-Term Investors

The Compound Cost of Losses: Why Avoiding Drawdowns Matters More Than Chasing Upside